Scaling and Load Balancing WildFly on OpenShift v3 With Fabric8
Did you enjoy the first ride with Fabric8 and OpenShift v3? There's more a lot more to come. After we got the first WildFly container up and running on Kubernetes, without having to deal with all it's inherent complexity, I think it is about time to start to scale and load balance WildFly.
Prerequisites
Make sure, you have the complete Vagrant, Fabric8, OpenShift v3, Kubernetes environment running. I walked you through the installation on Windows in my earlier blog post, but you can also give it a try on Google Container Engine or on OpenShift v3.
The Basics
What we did yesterday was to take our local Java EE 7 application and dockerize it based on latest jboss/wildfly:9.0.1.Final image. After that was done, we build the new myfear/wildfly-test:latest custom image and pushed it to the docker registry running on the vagrant image. The Fabric8 Maven plugin created the Kubernetes JSON for us and pushed it out to OpenShift for us. All this with the help of a nice and easy to use web-console. This post is going to re-use the same Java EE 7 example which you can grep from my github account.
Scaling Your Java EE Application on OpenShift With Fabric
One of the biggest features of Java EE application servers is scaling. Running high load on Kubernetes doesn't exactly match to how this was typically done in the past. With Kubernetes, you can scale Nodes and Minions, Replication Controllers and Pods according to your needs. Instead of launching new JVMs, you launch new container instances. And, we have learned, that Fabric8 is a very handy administration tool for Kubernetes, so we're going to scale our application a bit.
So, build the docker image of your Java EE 7 application and deploy it to Fabric8 with the following maven commands:
 No matter how often you hit refresh at this point, there is never going to be another pod id in this response. Of course not, we're only running one instance until now. Let's switch to the Fabric 8 console and scale up the pods. Switch to the "Apps" tab and click on the little green icon on the lower right to your application. In the overlay change the number of pods from one to three.
No matter how often you hit refresh at this point, there is never going to be another pod id in this response. Of course not, we're only running one instance until now. Let's switch to the Fabric 8 console and scale up the pods. Switch to the "Apps" tab and click on the little green icon on the lower right to your application. In the overlay change the number of pods from one to three.
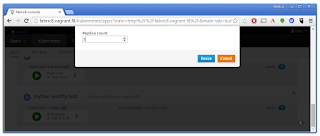
After a while, the change is reflected in your console and the pods go from downloading to green in a couple of seconds

Let's go back to our web-interface and hit refresh a couple of times. Nothing changes? What happened? What is wrong? Let me walk you through the architecture a little:
Overall Architecture
Did yesterdays blog post left your wondering? How did all the parts work together? Here's a little better overview for you. Spoiler alert: This is overly simplifying the OpenShift architecture. Please dig into the details on your own. I just want to give you a very focused view on scaling and load balancing with Fabric8 and OpenShift.

Everything relies on the OpenShift routing and management of the individual pods. Ports are exposed by containers and mapped through services. And this goes back to back from client to the running instance. And the central component, which does the routing is the HAProxy obviously. Which is a normal pod with one little exception: It has a public IP address. Let's see, what this thing does on OpenShift and how it is configured.
HAProxy As Standard Router On OpenShift
The default router implementation on OpenShift is HAProxy. It uses sticky sessions based on http-keep-alive. In addition, the router plug-in provides the service name and namespace to the underlying implementation. This can be used for more advanced configuration such as implementing stick-tables that synchronize between a set of peers.
The HAProxy router exposes a web listener for the HAProxy statistics. You can view the statistics in our example, by accessing http://vagrant.f8:1936/. It's a little tricky to find out the administrator password. This password and port are configured during the router installation, but they can be found by viewing the haproxy.conf file on the container. All you need find out is the pod, log-in to it, find the configuration file and read the password. In my case it was "6AtZV43YUk".

And if you really want to see, that it actually does work, you need to trick out the stickiness with a little curl magic. If you have Mysysgit installed on Windows, you can run the little batch script in my repository. It curl's a REST endpoint which puts out the POD ID which is serving the request:
It's about time to diver deeper into the developer tooling of Fabric8. Stay curious for more details in the next blog posts.
Prerequisites
Make sure, you have the complete Vagrant, Fabric8, OpenShift v3, Kubernetes environment running. I walked you through the installation on Windows in my earlier blog post, but you can also give it a try on Google Container Engine or on OpenShift v3.
The Basics
What we did yesterday was to take our local Java EE 7 application and dockerize it based on latest jboss/wildfly:9.0.1.Final image. After that was done, we build the new myfear/wildfly-test:latest custom image and pushed it to the docker registry running on the vagrant image. The Fabric8 Maven plugin created the Kubernetes JSON for us and pushed it out to OpenShift for us. All this with the help of a nice and easy to use web-console. This post is going to re-use the same Java EE 7 example which you can grep from my github account.
Scaling Your Java EE Application on OpenShift With Fabric
One of the biggest features of Java EE application servers is scaling. Running high load on Kubernetes doesn't exactly match to how this was typically done in the past. With Kubernetes, you can scale Nodes and Minions, Replication Controllers and Pods according to your needs. Instead of launching new JVMs, you launch new container instances. And, we have learned, that Fabric8 is a very handy administration tool for Kubernetes, so we're going to scale our application a bit.
So, build the docker image of your Java EE 7 application and deploy it to Fabric8 with the following maven commands:
mvn clean install docker:build
mvn fabric8:json fabric8:apply

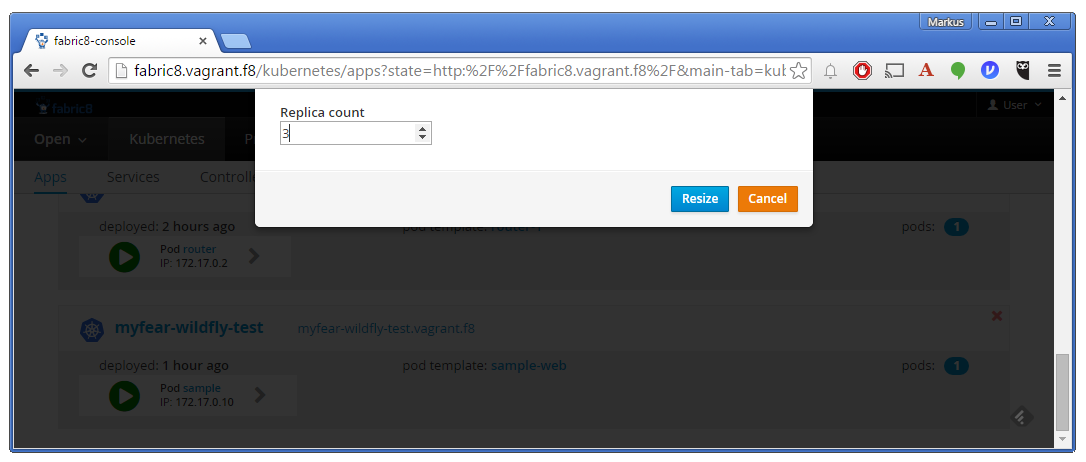
After a while, the change is reflected in your console and the pods go from downloading to green in a couple of seconds

Let's go back to our web-interface and hit refresh a couple of times. Nothing changes? What happened? What is wrong? Let me walk you through the architecture a little:
Overall Architecture
Did yesterdays blog post left your wondering? How did all the parts work together? Here's a little better overview for you. Spoiler alert: This is overly simplifying the OpenShift architecture. Please dig into the details on your own. I just want to give you a very focused view on scaling and load balancing with Fabric8 and OpenShift.

Everything relies on the OpenShift routing and management of the individual pods. Ports are exposed by containers and mapped through services. And this goes back to back from client to the running instance. And the central component, which does the routing is the HAProxy obviously. Which is a normal pod with one little exception: It has a public IP address. Let's see, what this thing does on OpenShift and how it is configured.
HAProxy As Standard Router On OpenShift
The default router implementation on OpenShift is HAProxy. It uses sticky sessions based on http-keep-alive. In addition, the router plug-in provides the service name and namespace to the underlying implementation. This can be used for more advanced configuration such as implementing stick-tables that synchronize between a set of peers.
The HAProxy router exposes a web listener for the HAProxy statistics. You can view the statistics in our example, by accessing http://vagrant.f8:1936/. It's a little tricky to find out the administrator password. This password and port are configured during the router installation, but they can be found by viewing the haproxy.conf file on the container. All you need find out is the pod, log-in to it, find the configuration file and read the password. In my case it was "6AtZV43YUk".
oc get pods
oc exec -it -p <POD_ID> bash
less haproxy.config

And if you really want to see, that it actually does work, you need to trick out the stickiness with a little curl magic. If you have Mysysgit installed on Windows, you can run the little batch script in my repository. It curl's a REST endpoint which puts out the POD ID which is serving the request:
{"name":"myfear","environment":"sample-web-jruh5"}
{"name":"myfear","environment":"sample-web-jruh5"}
{"name":"myfear","environment":"sample-web-jruh5"}
{"name":"myfear","environment":"sample-web-jruh5"}
{"name":"myfear","environment":"sample-web-jruh5"}
{"name":"myfear","environment":"sample-web-4oxjj"}
{"name":"myfear","environment":"sample-web-jruh5"}
{"name":"myfear","environment":"sample-web-pku0c"}
{"name":"myfear","environment":"sample-web-4oxjj"}
{"name":"myfear","environment":"sample-web-jruh5"}
{"name":"myfear","environment":"sample-web-pku0c"}
It's about time to diver deeper into the developer tooling of Fabric8. Stay curious for more details in the next blog posts.

Post a Comment